


SAM(segment anything model)分割一切 Demo测试及API调用
SAM(segment anything model)分割一切 Demo测试及API调用
版权声明:本文为CSDN博主「Alexa2077」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/Alexa_/article/details/130277707
一.SAM介绍
1.1.介绍
Meta发布一种新的语义分割模型,Segment Anything Model (SAM)。仅仅3天时间该项目在Github就收获了1.8万个star,火爆程度可见一斑。有人甚至称之为CV领域的GPT时刻。SAM都做了什么让大家如此感兴趣?
-SAM与传统单纯的语义分割方式不同,加入了Prompt机制,可以将文字、坐标点、坐标框等作为辅助信息优化分割结果,这一方面增加了–交互的灵活性,另一方面这也是解决图像分割中尺度问题的一次有益尝试。 -当在识别要分割的对象时遇到不确定性,SAM 能够生成多个有效掩码。 -SAM 的自动分割模式可以识别图像中存在的所有潜在对象并生成蒙版。 -贡献了目前全球最大的语义分割数据集。
关于更多SAM知识可以阅读论文或者文章最后知乎话题链接。
1.2.项目链接
项目地址:https://github.com/facebookresearch/segment-anything
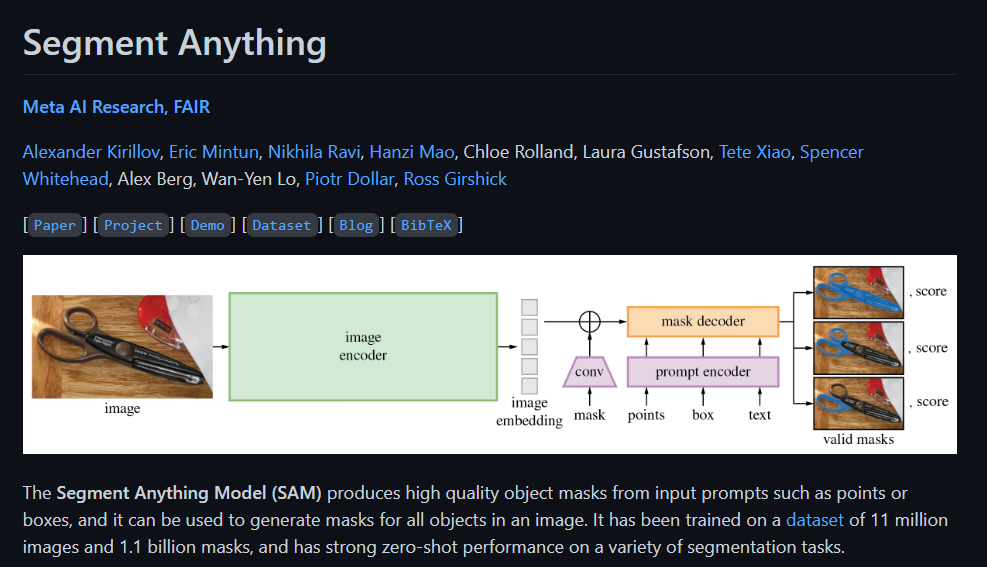
论文名称与地址:Segment Anything
https://arxiv.org/pdf/2304.02643.pdf

Demo地址:https://segment-anything.com/

二.Demo-Test:
在这里将尝试使用Dome进行简单测试:进入网址:https://segment-anything.com/
2.1.Demo功能介绍
2.1.1.首页就是这个SAM,点击try demo,可以选择它的自带图片,也可以自己添加。
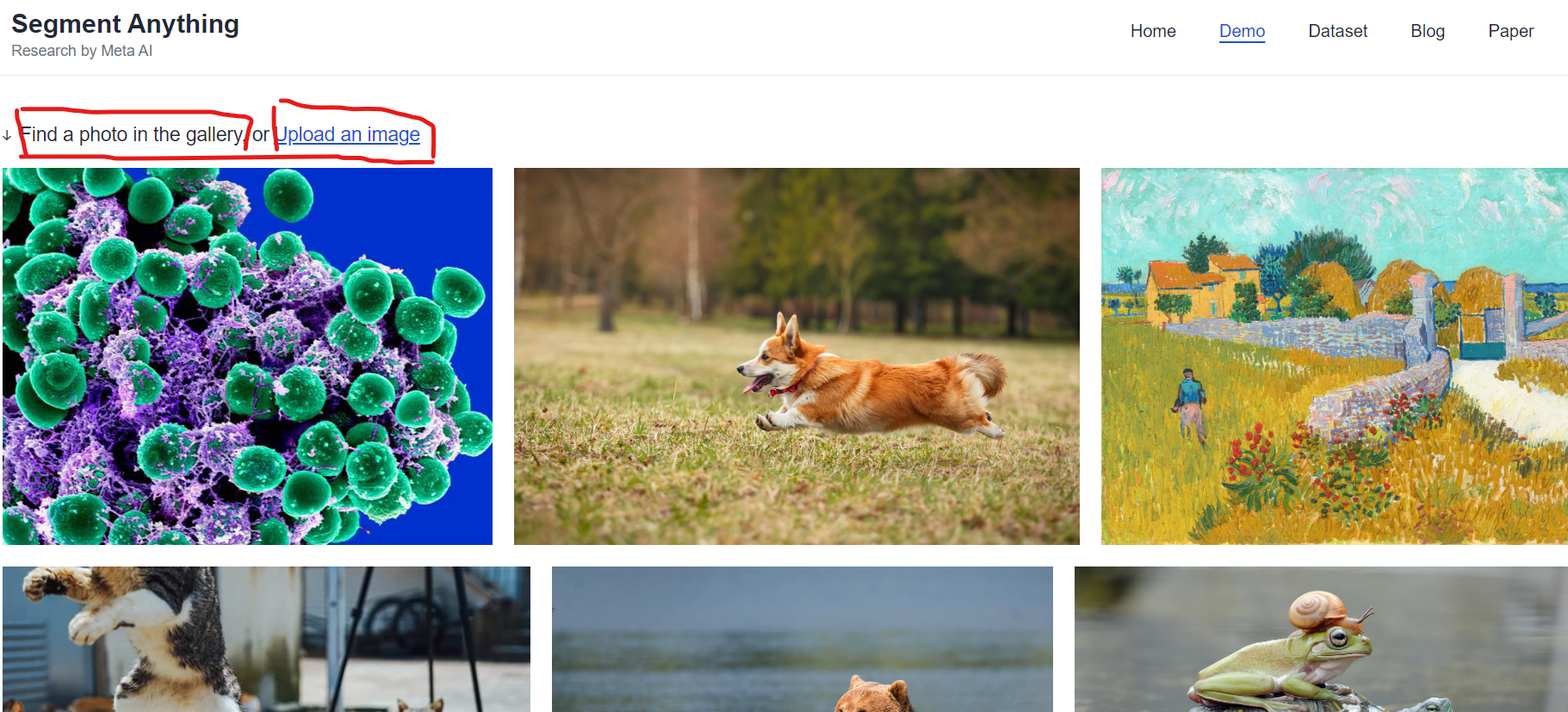
当你进入体验页面时,网页左侧有四个选项。下面一一介绍:
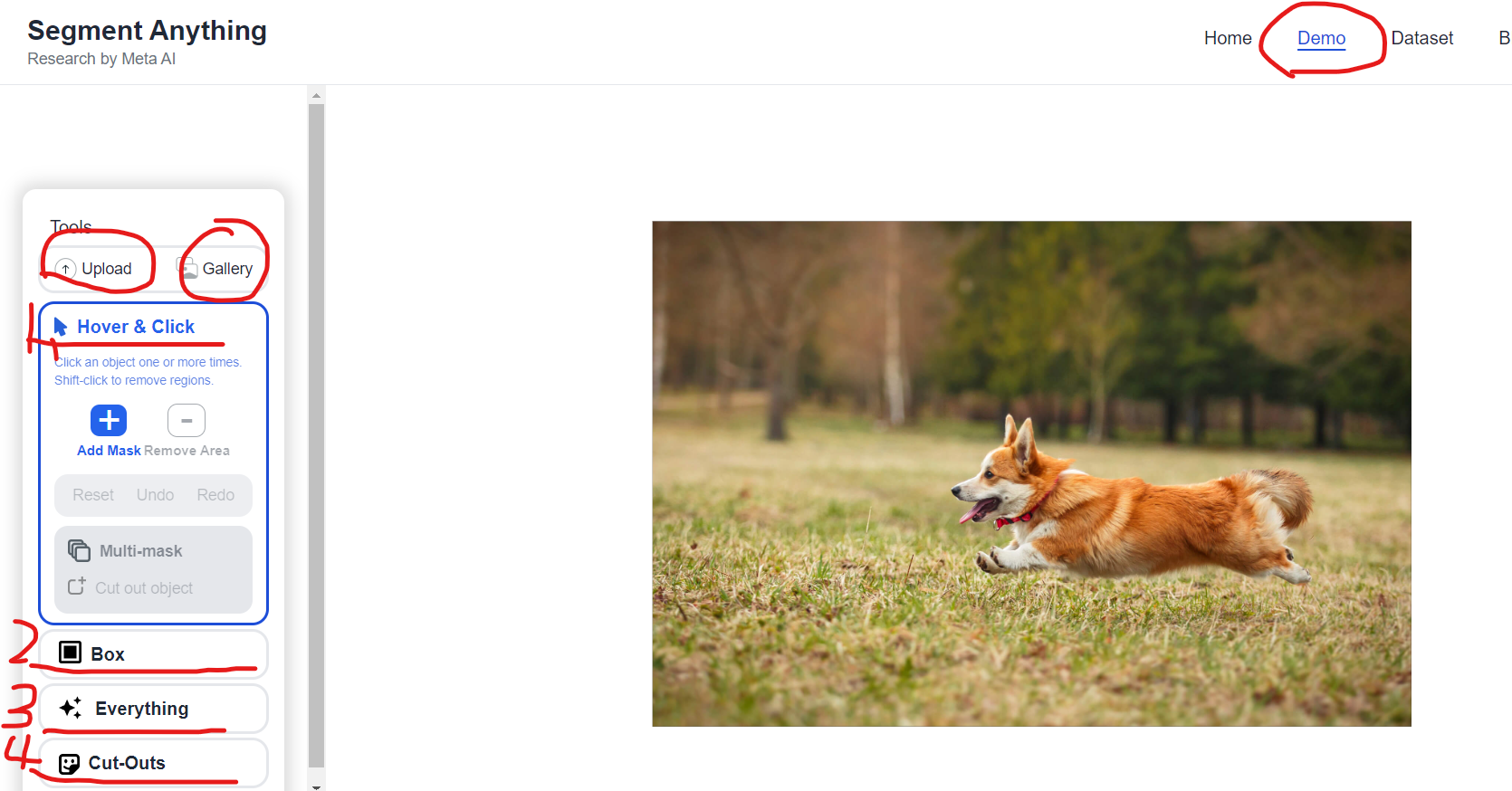
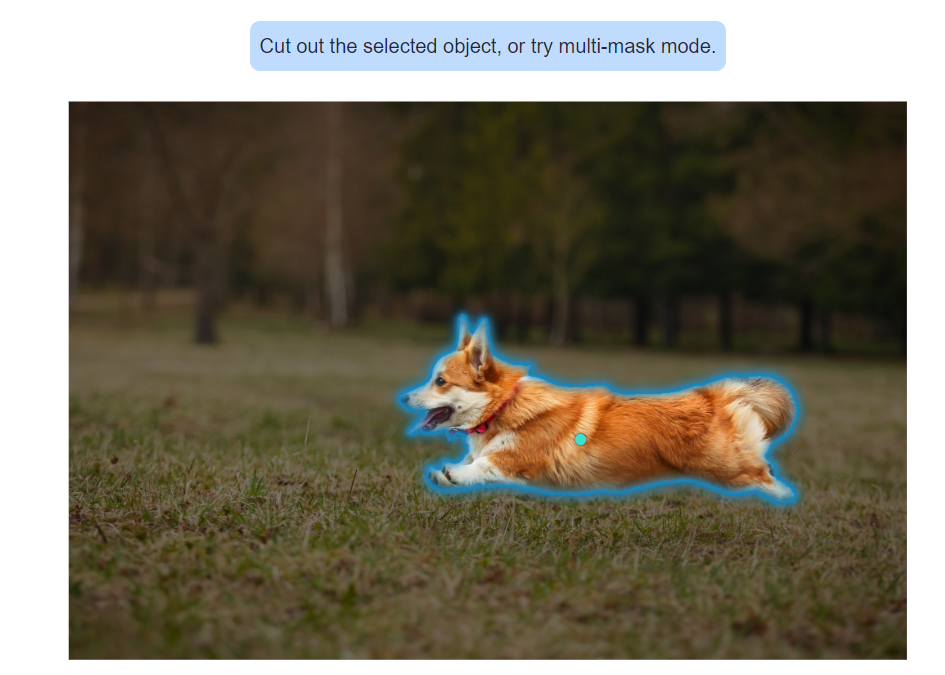
(1) Hover &Click: 这个选项可以悬浮划过鼠标,看每个物体的分割效果,也可以点击想要提取的物体,根据你点击的点,自动提取物体范围生成边缘。
(2) Box:框住想选的物体,识别物体边缘。

(3) Everything: 识别出图像中所有的物体,并分割。

(4) Cut-outs:当你在前三个选项里选择Cut out Object后,将会在这个选项里得到分割后的物体
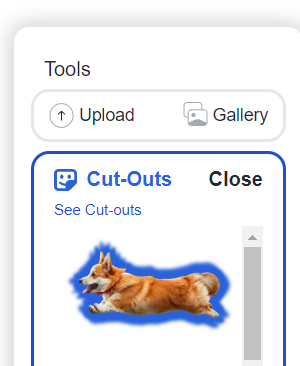
2.1.2.自己上传图片测试:
自然图像:


医学图像:
该图片是测试图片,从网站上下载的。
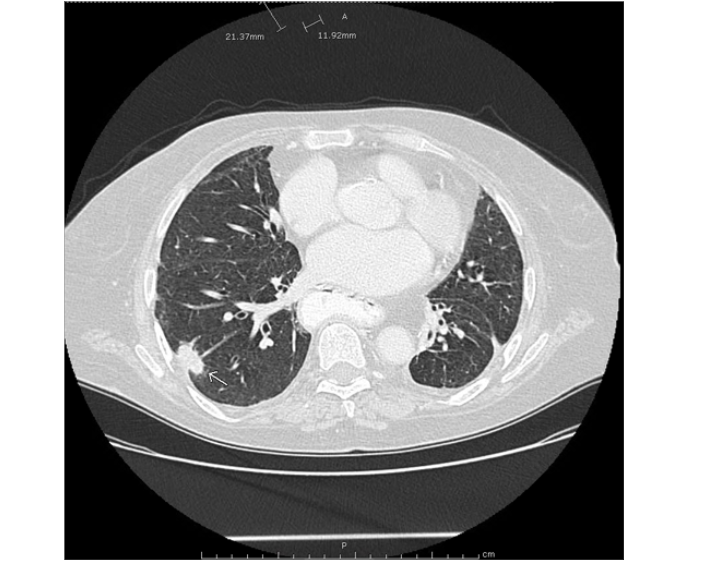
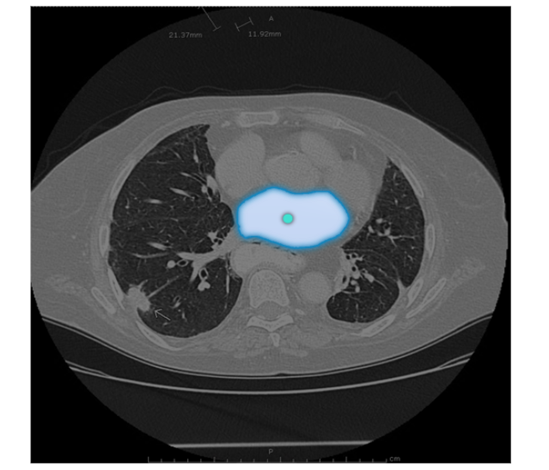
以上就是体验部分的全部。 因为官方的代码是开源的,所以也可以在python里进行安装和调用。 第三节主要讲如何进行配置环境以及简单的调用方法,并测试医学图像效果。
三:Code-Test
3.1.下载:
从github上下载开源项目到本地:https://github.com/facebookresearch/segment-anything
3.2.配置环境:
该代码需要python>=3.8,以及pytorch>=1.7和torchvision>=0.8 先安装一些基础依赖 pip install opencv-python pycocotools matplotlib onnxruntime onnx
(可能在下载环境依赖的时候,出现问题,可以分开多次下载以上基础依赖)
3.3.下载预训练模型:
下载安装完成以及配置环境完成后,需要先下载官方训练好的模型,一共有三个选择,官方说法是有不同长度的主干网络: 这里一共提供了H、L、B三种不同size的模型。
链接:https://github.com/facebookresearch/segment-anything#model-checkpoints

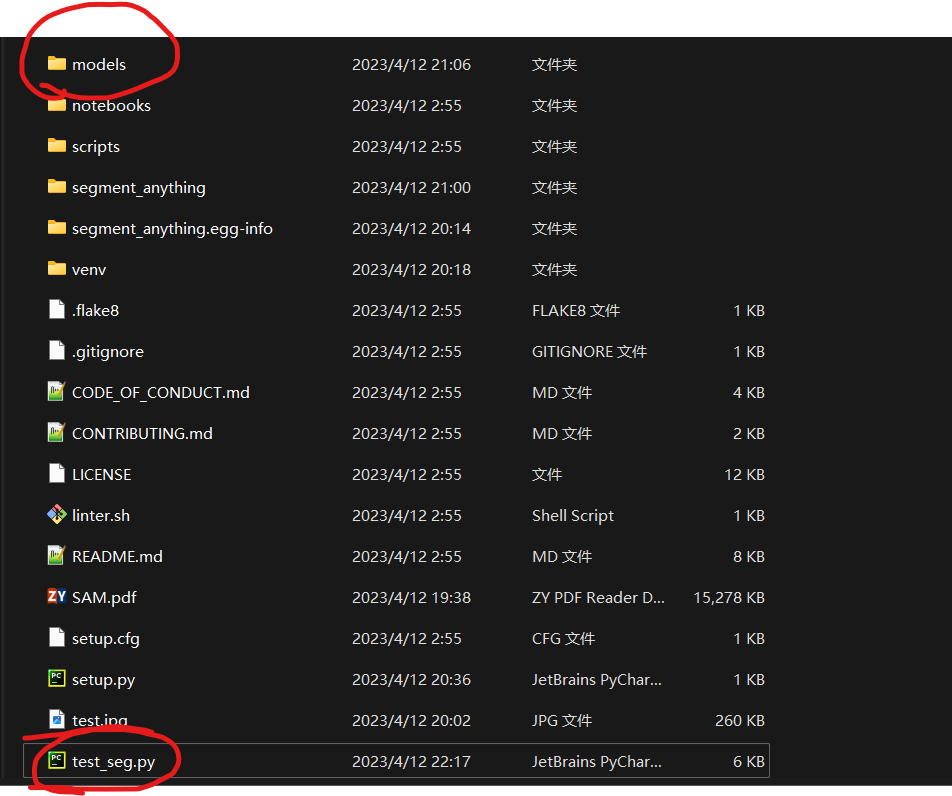
在项目里建models文件夹,并把三个模型放入,便于后面调用:测试文档见:test_seg.py
整个项目文档,包括三个模型,下述代码,都已放到网盘上,有需要的可以整体下载,可能比较大,因为上述预训练好的大模型就已经2.4G: 各位好兄弟感觉这篇文章有用的话,帮忙点个赞!!!
链接已更新,永久有效! 百度网盘链接: 链接:https://pan.baidu.com/s/1B6lxDSj0saALsM_zqTpl2w 提取码:8nde
3.4.SAM模型的使用方法
3.4.1.导入相关库并定义显示函数
下面导入了运行所需的第三方库,以及定义了用于展示点、方框以及分割目标的函数。
import numpy as np
import torch
import matplotlib.pyplot as plt
import cv2
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30/255, 144/255, 255/255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
def show_points(coords, labels, ax, marker_size=375):
pos_points = coords[labels==1]
neg_points = coords[labels==0]
ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white', linewidth=1.25)
ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white', linewidth=1.25)
def show_box(box, ax):
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0,0,0,0), lw=2))
3.4.2.导入待分割图片
image = cv2.imread('test.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(10,10))
plt.imshow(image)
plt.axis('on')
plt.show()
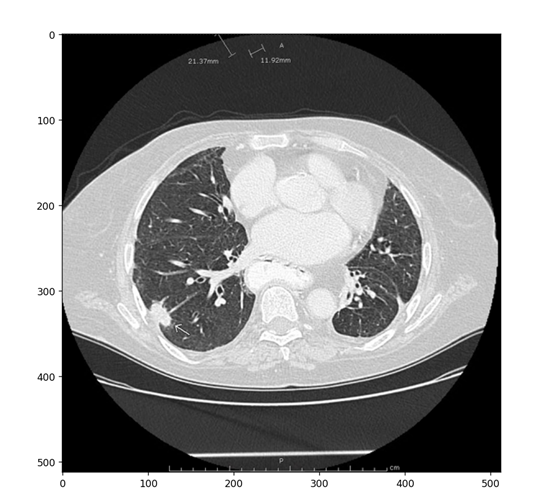
3.5.使用不同提示方法进行目标分割
首先,加载SAM预训练模型
import sys
sys.path.append("..")
from segment_anything import sam_model_registry, SamPredictor
sam_checkpoint = "./models/sam_vit_b_01ec64.pth"
model_type = "vit_b"
device = "cpu" # or "cuda"
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
predictor = SamPredictor(sam)
通过调用SamPredictor.set_image函数,将输入的图像进行编码,SamPredictor 会使用这些编码进行后续的目标分割任务。
predictor.set_image(image)
在图片上,选择一个点。点的输入格式为(x, y)和并表示出点所带有的标签1(前景点)或0(背景点)。可以输入多个点,在这里我们先只用一个点,选择的点会显示为一个五角星的标记。
3.5.1 方法一:使用单个提示点进行目标分割
# 单点 prompt 输入格式为(x, y)和并表示出点所带有的标签1(前景点)或0(背景点)。
input_point = np.array([[270, 240]]) # 标记点
input_label = np.array([1]) # 点所对应的标签
plt.figure(figsize=(10,10))
plt.imshow(image)
show_points(input_point, input_label, plt.gca())
plt.axis('on')
plt.show()
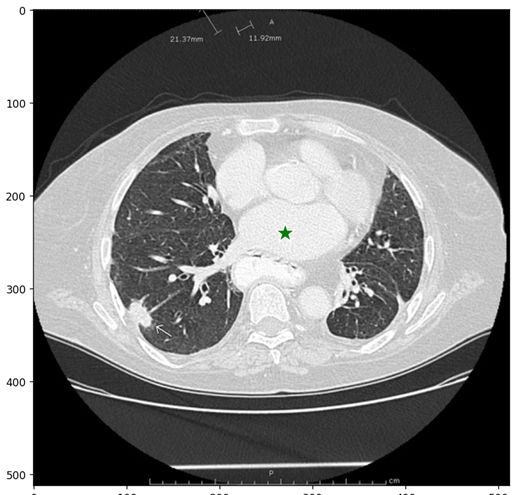
用 SamPredictor.predict进行分割,模型会返回这些分割目标对应的置信度。
masks, scores, logits = predictor.predict(
point_coords=input_point,
point_labels=input_label,
multimask_output=True,
)
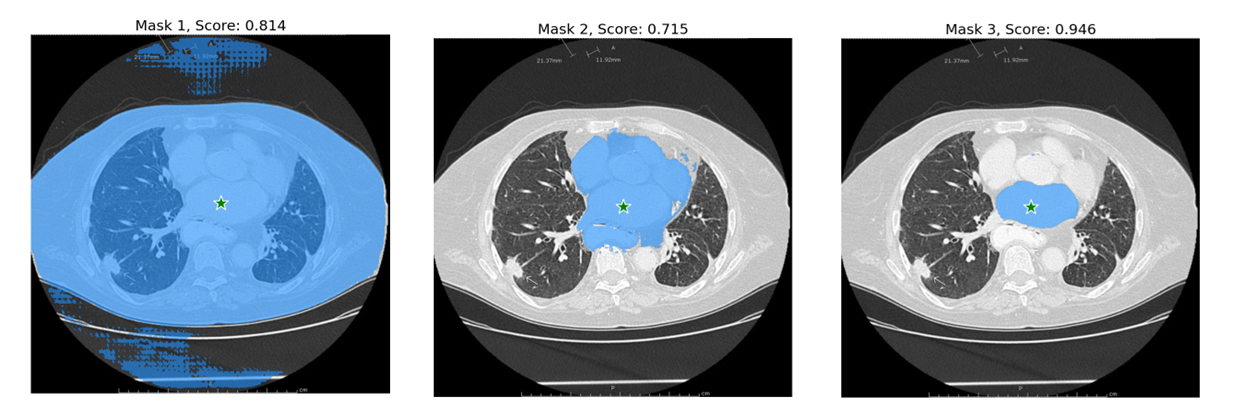
参数说明: point_coords: 提示的坐标点位置 point_labels: 提示点对应的类型,1前景,0背景 boxes: 提示的方框 multimask_output: 多目标输出还是但目标输出True or False multimask_output=True (默认),SAM模型会输出3个分割目标和对应的置信度scores。这个设置主要是用于面对歧义的提示点,因为一个提示点可能在多个分割的目标内部,multimask_output=True 能够将包含该提示点的所有目标都分割出来。 如下面示例所示:2种车窗户、还有整个车均包含了五角星的提示点。 输出置信度不同的分割图:
print(masks.shape) # (number_of_masks) x H x W
# 三个置信度不同的图
for i, (mask, score) in enumerate(zip(masks, scores)):
plt.figure(figsize=(10,10))
plt.imshow(image)
show_mask(mask, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.title(f"Mask {i+1}, Score: {score:.3f}", fontsize=18)
plt.axis('off')
plt.show()
3.5.2 方法二:使用多个提示点进行目标分割
单个提示点通常会存在歧义的影响,因为可能多个目标均包含该点。为了得到我们想要的单个目标,我们可以在目标上进行多个点的提示,以获取该目标的分割结果。如果我们想要剔除,可以使用背景点(label=0),将其他部分剔除掉。
多点prompt
input_point = np.array([[270, 240], [260, 240]])
input_label = np.array([1, 1])
mask_input = logits[np.argmax(scores), :, :] # Choose the model's best mask
masks, _, _ = predictor.predict(
point_coords=input_point,
point_labels=input_label,
mask_input=mask_input[None, :, :],
multimask_output=False,
)
print(masks.shape)
plt.figure(figsize=(10,10))
plt.imshow(image)
show_mask(masks, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.axis('off')
plt.show()
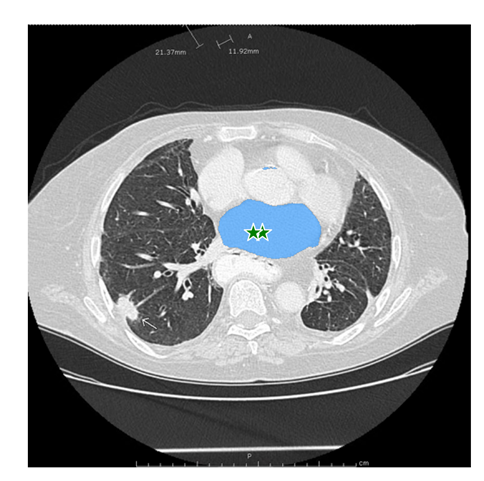
3.5.3 方法三:用方框指定一个目标进行分割
SAM模型可以用一个方框作为输入,格式为[x1,y1,x2,y2]。来进行单个目标的分割,如下面所示,通过方框对车的轮子进行分割。
# 方框prompt SAM模型可以用一个方框作为输入,格式为[x1,y1,x2,y2],左上,右下。来进行单个目标的分割
def box_prompt():
input_box = np.array([200, 200, 370, 290])
masks, _, _ = predictor.predict(
point_coords=None,
point_labels=None,
box=input_box[None, :],
multimask_output=False,
)
plt.figure(figsize=(10, 10))
plt.imshow(image)
show_mask(masks[0], plt.gca())
show_box(input_box, plt.gca())
plt.axis('off')
plt.show()
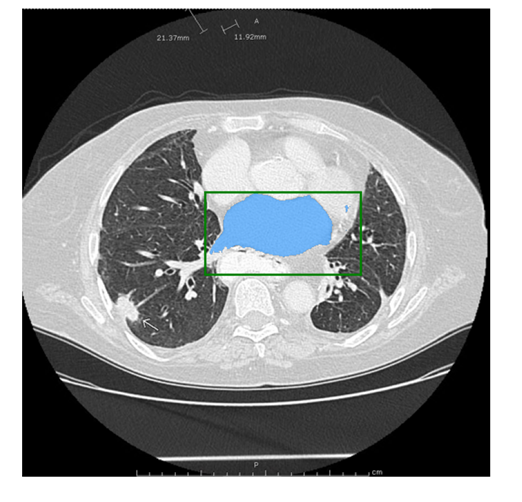
3.5.4 将点与方框结合,进行目标分割
通过方框和点配合使用,更加准确。
#将点与方框结合,进行目标分割
def box_point_prompt():
input_box = np.array([200, 200, 370, 290])
input_point = np.array([[270, 240]])
input_label = np.array([1])
masks, _, _ = predictor.predict(
point_coords=input_point,
point_labels=input_label,
box=input_box,
multimask_output=False,
)
plt.figure(figsize=(10, 10))
plt.imshow(image)
show_mask(masks[0], plt.gca())
show_box(input_box, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.axis('off')
plt.show()
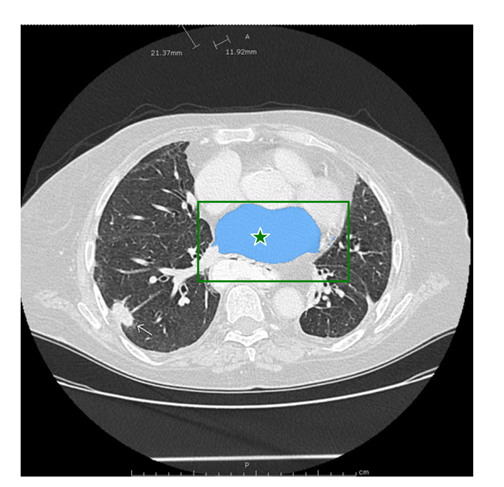
3.5.5 方法五:多个方框同时输入,进行多目标分割
通过同时输入多个方框,可用于分割不同方框中的目标。
多个方框同时输入,进行多目标分割
def multi_box_prompt():
input_boxes = torch.tensor([
[200, 200, 350, 290],
[220, 300, 290, 340],
], device=predictor.device)
transformed_boxes = predictor.transform.apply_boxes_torch(input_boxes, image.shape[:2])
masks, _, _ = predictor.predict_torch(
point_coords=None,
point_labels=None,
boxes=transformed_boxes,
multimask_output=False,
)
print(masks.shape) # x H x W
plt.figure(figsize=(10, 10))
plt.imshow(image)
for mask in masks:
show_mask(mask.cpu().numpy(), plt.gca(), random_color=True)
for box in input_boxes:
show_box(box.cpu().numpy(), plt.gca())
plt.axis('off')
plt.show()
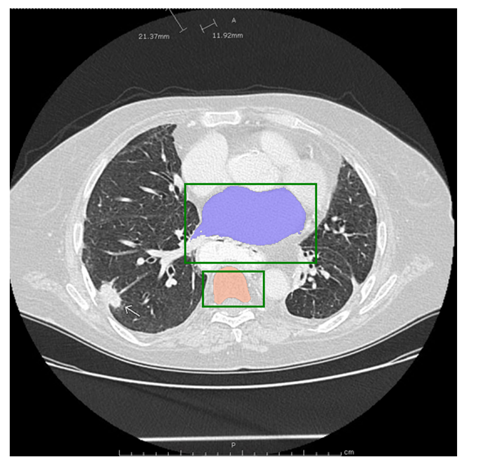
以上便是SAM模型的使用方法,可以通过不同的提示方式得到不同的分割结果。总体来说,效果还是很不错的,关键是居然还可以在CPU环境下快速运行。
四.扩展阅读:
分割一切还不够,还要检测一切、生成一切,SAM二创开始了 https://github.com/IDEA-Research/Grounded-Segment-Anything
五.参考文章:
介绍: SAM - 分割一切图像【AI大模型】
https://blog.csdn.net/shebao3333/article/details/130037926
【segment-anything】- Meta 开源万物可分割 AI 模型 - Taylor的文章 - 知乎 https://zhuanlan.zhihu.com/p/620004338
知乎话题:Meta 发布图像分割论文 Segment Anything,将给 CV 研究带来什么影响?
-
知乎 https://www.zhihu.com/question/593914819 话题: Meta 发布 AI 模型 SAM,有哪些技术亮点?
-
知乎 https://www.zhihu.com/question/593996820 Segment Anything Model (SAM)——卷起来了,那个号称分割一切的CV大模型他来了 https://blog.csdn.net/Together_CZ/article/details/129991631 代码:
【CV大模型SAM(Segment-Anything)】真是太强大了,分割一切的SAM大模型使用方法:可通过不同的提示得到想要的分割目标
https://blog.csdn.net/qq_42589613/article/details/130061434
Meta 发布图像分割论文 Segment Anything,将给 CV 研究带来什么影响? - Glenn的回答 - 知乎
https://www.zhihu.com/question/593914819/answer/2971671307
SAM的使用体验和方法(简略教程) - 沈熙载的文章 - 知乎 https://zhuanlan.zhihu.com/p/620013907